



پیش بینی سری زمانی در پایتون - قسمت 2
پنجره سازی داده ها
مدل های موجود در این مجموعه آموزشی بر اساس پنجره ای از نمونه های متوالی داده ها، مجموعه ای از پیش بینی ها را ایجاد می کنند.
ویژگی های اصلی پنجره های ورودی عبارتند از:
- عرض (تعداد مراحل زمان) پنجره های ورودی و برچسب
- فاصله زمانی بین آنها.
- کدام ویژگی ها به عنوان ورودی، برچسب یا هر دو مورد استفاده قرار می گیرند.
این آموزش انواع مختلفی را ایجاد می کند (از جمله مدل های Linear ،DNN ،CNN و RNN) و از آنها برای هر دو استفاده می کند:
- پیش بینی های تک خروجی و چند خروجی.
- پیش بینی های یک مرحله ای و چند مرحله ای.
این بخش بر اجرای پنجره سازی داده ها متمرکز است تا بتوان از آن برای همه مدل ها استفاده مجدد کرد.
بسته به وظیفه و نوع مدل شما می خواهید انواع مختلفی از پنجره های داده را ایجاد کنید. در اینجا چند نمونه آورده شده است:
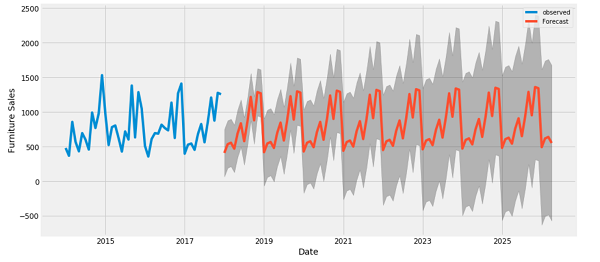
- به عنوان مثال، برای پیش بینی واحد 24 ساعته در آینده، با توجه به تاریخ 24 ساعته، ممکن است پنجره ای به این شکل تعریف کنید:
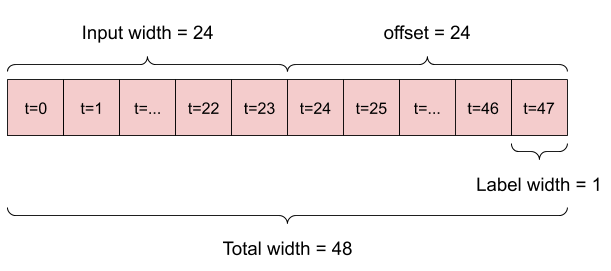
- مدلی که با توجه به 6 ساعت تاریخ، یک ساعت آینده را پیش بینی کند، به پنجره ای مانند این نیاز دارد:

بقیه این بخش کلاس WindowGenerator را تعریف می کند. این کلاس می تواند:
- همانطور که در نمودارهای بالا نشان داده شده است، شاخص ها و جبران ها را کنترل کنید.
- پنجره های ویژگی ها را به یک جفت (features, labels) تقسیم کنید.
- محتوای پنجره های حاصل را رسم کنید.
- با استفاده از
tf.data.Datasetدسته ای از این پنجره ها را از طریق آموزش، ارزیابی و داده های آزمایشی تولید کنید.
1. شاخص ها و جبران ها (Indexes and offsets)
با ایجاد کلاس WindowGenerator شروع کنید. روش __init__ شامل تمام منطق لازم برای شاخص های ورودی و برچسب است.
همچنین از فریم داده های آموزش، ارزیابی و آزمایش به عنوان ورودی استفاده می شود. بعداً به tf.data.Dataset ویندوز تبدیل می شوند.
class WindowGenerator():
def __init__(self, input_width, label_width, shift,
train_df=train_df, val_df=val_df, test_df=test_df,
label_columns=None):
# Store the raw data.
self.train_df = train_df
self.val_df = val_df
self.test_df = test_df
# Work out the label column indices.
self.label_columns = label_columns
if label_columns is not None:
self.label_columns_indices = {name: i for i, name in
enumerate(label_columns)}
self.column_indices = {name: i for i, name in
enumerate(train_df.columns)}
# Work out the window parameters.
self.input_width = input_width
self.label_width = label_width
self.shift = shift
self.total_window_size = input_width + shift
self.input_slice = slice(0, input_width)
self.input_indices = np.arange(self.total_window_size)[self.input_slice]
self.label_start = self.total_window_size - self.label_width
self.labels_slice = slice(self.label_start, None)
self.label_indices = np.arange(self.total_window_size)[self.labels_slice]
def __repr__(self):
return '\n'.join([
f'Total window size: {self.total_window_size}',
f'Input indices: {self.input_indices}',
f'Label indices: {self.label_indices}',
f'Label column name(s): {self.label_columns}'])این کد برای ایجاد 2 پنجره ای است که در نمودارهای ابتدای این بخش نشان داده شده است:
w1 = WindowGenerator(input_width=24, label_width=1, shift=24,
label_columns=['T (degC)'])
w1Total window size: 48 Input indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23] Label indices: [47] Label column name(s): ['T (degC)']
w2 = WindowGenerator(input_width=6, label_width=1, shift=1,
label_columns=['T (degC)'])
w2Total window size: 7 Input indices: [0 1 2 3 4 5] Label indices: [6] Label column name(s): ['T (degC)']
2. تقسیم (Split)
با توجه به لیست ورودی های متوالی، روش split_window آنها را به پنجره ورودی و پنجره برچسب تبدیل می کند.
مثال w2، در بالا، به صورت زیر تقسیم می شود:
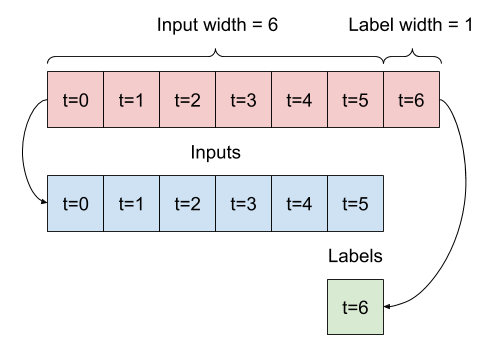
این نمودار محور features داده را نشان نمی دهد، اما این تابع split_window همچنین label_columns را مدیریت می کند، بنابراین می تواند برای هر دو نمونه خروجی و چند خروجی استفاده شود.
def split_window(self, features):
inputs = features[:, self.input_slice, :]
labels = features[:, self.labels_slice, :]
if self.label_columns is not None:
labels = tf.stack(
[labels[:, :, self.column_indices[name]] for name in self.label_columns],
axis=-1)
# Slicing doesn't preserve static shape information, so set the shapes
# manually. This way the `tf.data.Datasets` are easier to inspect.
inputs.set_shape([None, self.input_width, None])
labels.set_shape([None, self.label_width, None])
return inputs, labels
WindowGenerator.split_window = split_windowاین را امتحان کنید:
# Stack three slices, the length of the total window:
example_window = tf.stack([np.array(train_df[:w2.total_window_size]),
np.array(train_df[100:100+w2.total_window_size]),
np.array(train_df[200:200+w2.total_window_size])])
example_inputs, example_labels = w2.split_window(example_window)
print('All shapes are: (batch, time, features)')
print(f'Window shape: {example_window.shape}')
print(f'Inputs shape: {example_inputs.shape}')
print(f'labels shape: {example_labels.shape}')All shapes are: (batch, time, features) Window shape: (3, 7, 19) Inputs shape: (3, 6, 19) labels shape: (3, 1, 1)
به طور معمول داده ها در TensorFlow به آرایه هایی بسته می شوند که بیرونی ترین شاخص در نمونه ها باشد (بعد "دسته"). شاخص های میانی ابعاد "زمان" یا "فضا" (عرض، ارتفاع) هستند. درونی ترین شاخص ها ویژگی ها هستند.
کد فوق دسته ای از 3 ویندوز 7 گام 7 برابری را شامل می شود که دارای 19 ویژگی در هر مرحله است. آنها را به دسته ای از 6 بار گام، 19 ورودی ویژگی و یک برچسب 1 بار گام 1 ویژگی تقسیم می کند. برچسب فقط یک ویژگی دارد زیرا WindowGenerator با:
label_columns=['T (degC)']
مقدار دهی اولیه شد. در ابتدا این آموزش مدل هایی را تولید می کند که برچسب های تک خروجی را پیش بینی می کنند.
3. طرح
در اینجا یک روش طرح است که اجازه می دهد یک تجسم ساده از پنجره تقسیم وجود داشته باشد:
w2.example = example_inputs, example_labelsdef plot(self, model=None, plot_col='T (degC)', max_subplots=3):
inputs, labels = self.example
plt.figure(figsize=(12, 8))
plot_col_index = self.column_indices[plot_col]
max_n = min(max_subplots, len(inputs))
for n in range(max_n):
plt.subplot(3, 1, n+1)
plt.ylabel(f'{plot_col} [normed]')
plt.plot(self.input_indices, inputs[n, :, plot_col_index],
label='Inputs', marker='.', zorder=-10)
if self.label_columns:
label_col_index = self.label_columns_indices.get(plot_col, None)
else:
label_col_index = plot_col_index
if label_col_index is None:
continue
plt.scatter(self.label_indices, labels[n, :, label_col_index],
edgecolors='k', label='Labels', c='#2ca02c', s=64)
if model is not None:
predictions = model(inputs)
plt.scatter(self.label_indices, predictions[n, :, label_col_index],
marker='X', edgecolors='k', label='Predictions',
c='#ff7f0e', s=64)
if n == 0:
plt.legend()
plt.xlabel('Time [h]')
WindowGenerator.plot = plotاین طرح ورودی ها، برچسب ها و پیش بینی های (بعدا) را بر اساس زمانی که مورد به آن اشاره می کند تراز می کند:
w2.plot()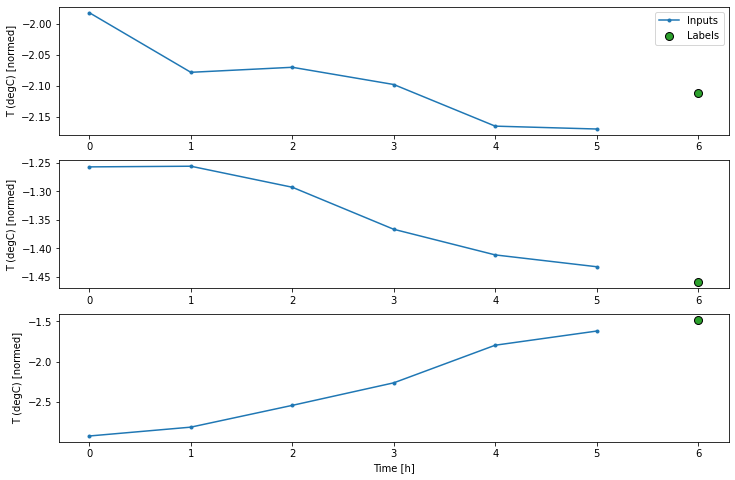
می توانید ستون های دیگر را رسم کنید، اما در مثال پیکربندی پنجره w2 فقط برچسب هایی برای ستون (T (degC وجود دارد.
w2.plot(plot_col='p (mbar)')
4- ایجاد tf.data.Dataset
سرانجام این روش make_dataset به یک سری زمان DataFrame نیاز دارد و آن را به یک جفت tf.data.Dataset از جفت (input_window, label_window) با استفاده از تابع preprocessing.timeseries_dataset_from_array تبدیل می کند.
def make_dataset(self, data):
data = np.array(data, dtype=np.float32)
ds = tf.keras.preprocessing.timeseries_dataset_from_array(
data=data,
targets=None,
sequence_length=self.total_window_size,
sequence_stride=1,
shuffle=True,
batch_size=32,)
ds = ds.map(self.split_window)
return ds
WindowGenerator.make_dataset = make_datasetشی WindowGenerator داده های آموزش، اعتبار سنجی و آزمون را در خود جای داده است. برای دسترسی به آنها خصوصیات را به عنوان tf.data.Datasets با استفاده از روش make_dataset فوق اضافه کنید. برای دسترسی آسان و رسم نمودار، یک دسته نمونه استاندارد نیز اضافه کنید:
@property
def train(self):
return self.make_dataset(self.train_df)
@property
def val(self):
return self.make_dataset(self.val_df)
@property
def test(self):
return self.make_dataset(self.test_df)
@property
def example(self):
"""Get and cache an example batch of `inputs, labels` for plotting."""
result = getattr(self, '_example', None)
if result is None:
# No example batch was found, so get one from the `.train` dataset
result = next(iter(self.train))
# And cache it for next time
self._example = result
return result
WindowGenerator.train = train
WindowGenerator.val = val
WindowGenerator.test = test
WindowGenerator.example = exampleاکنون شی WindowGenerator به شما امکان دسترسی به اشیا tf.data.Dataset را می دهد، بنابراین می توانید به راحتی داده ها را تکرار کنید.
ویژگی Dataset.element_spec ساختار، نوع و شکل عناصر مجموعه داده را به شما می گوید.
# Each element is an (inputs, label) pair
w2.train.element_spec(TensorSpec(shape=(None, 6, 19), dtype=tf.float32, name=None), TensorSpec(shape=(None, 1, 1), dtype=tf.float32, name=None))
تکرار بیش از یک Dataset باعث تولید دسته های بلوکی می شود:
for example_inputs, example_labels in w2.train.take(1):
print(f'Inputs shape (batch, time, features): {example_inputs.shape}')
print(f'Labels shape (batch, time, features): {example_labels.shape}')Inputs shape (batch, time, features): (32, 6, 19) Labels shape (batch, time, features): (32, 1, 1)


مدیر سایت: بهزاد سرهادی کارشناس ارشد مهندسی آب
شناسه تلگرام مدیر سایت: SubBasin@
نشانی ایمیل: behzadsarhadi@gmail.com
(سوالات تخصصی را در گروه تلگرام ارسال کنید)
_______________________________________________________
پروژه تخصصی در لینکدین



 در منابع آب
در منابع آب


























نظرات (۰)