



آشنایی با پلاتفرم آنلاین مدل سازی هیدرولوژیکی WFLOW

معرفی
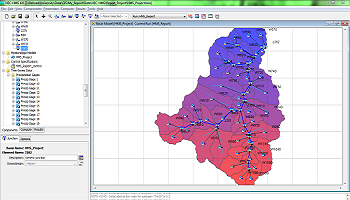
این سند جریان پلاتفرم مدل سازی هیدرولوژیکی توزیع شده را توصیف می کند. wflow بخشی از پروژه OpenStreams Deltares است. Wflow شامل مجموعه ای از برنامه های پایتون می شود که می توانند در خط فرمان اجرا شوند و شبیه سازی های هیدرولوژیکی انجام دهند. این مدل ها بر اساس چارچوب PCRaster پایتون (www.pcraster.eu) است. در wflow این چارچوب گسترش یافته است (کلاس wf_DynamicFramework) به طوری که مدل های ساخته شده با استفاده از این چارچوب را می توان با استفاده از API کنترل کرد. لینک به BMI و OpenDA ایجاد شده است. تمام کد در github در دسترس است و تحت نسخه 3.0 GPL توزیع شده است.
















 را با تمرین در یک مجموعه دادهیاد میگیرد، آنجا که
را با تمرین در یک مجموعه دادهیاد میگیرد، آنجا که  تعداد ابعاد ورودی است و o تعداد از ابعاد خروجی با توجه به مجموعه ای از ویژگی های
تعداد ابعاد ورودی است و o تعداد از ابعاد خروجی با توجه به مجموعه ای از ویژگی های  و یک هدف y، می توان یک تقریبنده تابع غیر خطی را برای هر دو طبقه بندی یا رگرسیون یاد گرفت. این تفاوت از رگرسیون لجستیک است، در حالی که بین ورودی و لایه خروجی، می تواند یک یا چند لایه غیر خطی وجود داشته باشد که لایه های مخفی هستند. شکل 1 یک MLP مخفی با خروجی اسکالر را نشان می دهد.
و یک هدف y، می توان یک تقریبنده تابع غیر خطی را برای هر دو طبقه بندی یا رگرسیون یاد گرفت. این تفاوت از رگرسیون لجستیک است، در حالی که بین ورودی و لایه خروجی، می تواند یک یا چند لایه غیر خطی وجود داشته باشد که لایه های مخفی هستند. شکل 1 یک MLP مخفی با خروجی اسکالر را نشان می دهد.


























آب های زیرزمینی - مبانی و مفاهیم و پروژه های تخصصی
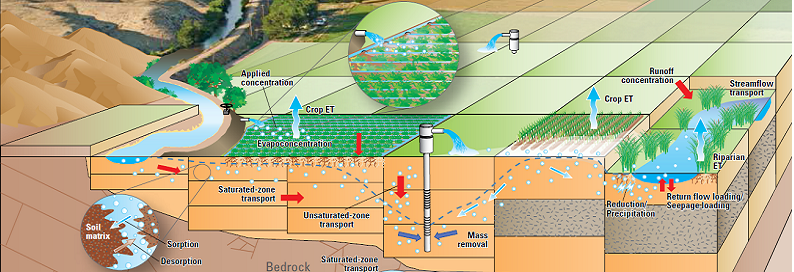
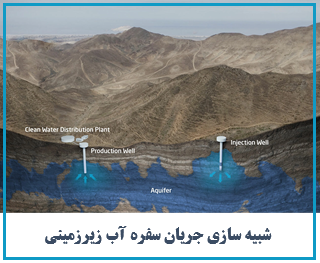
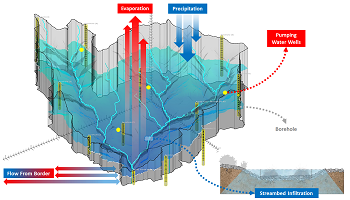
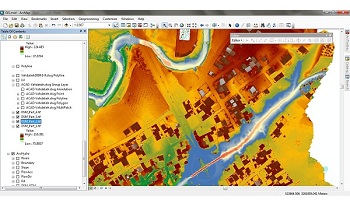
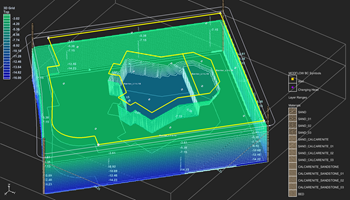
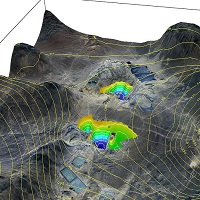
آبخوان ها و سفره های آب زیرزمینی علی رقم آنکه بخش مهم ذخایر طبیعی آب شیرین جهان را تشکیل می دهند، به دلیل ماهیت پنهان از چشم خود، همواره بیشترین فشار ها را در استفاده های بی رویه بر خود تحمل کرده و تنش اساسی بیلان داشته های آبی یک محدوده در این بخش رخ داده است. مدل ها و شبیه سازهای کامپیوتری شناخته شده ای در این زمینه وجود دارد که از گستردگی کاملی به منظور مطالعات و مدیریت برخوردار است.
آب های سطحی - مبانی و مفاهیم و پروژه های تخصصی
آب های سطحی، اگرچه در دسترس ترین منابع برای بشر محسوب می شوند، اما از نظر پایدار بسیار آسیب پذیر و در عین حال بیشترین آلودگی را دریافت و حمل می کنند. همچنین حوادث شدید آب و هوایی مشخصا و حدقل به صورت بصری، بیشتر بر روی این دسته از منابع قابل شناسایی است. شناخت درست آب های سطحی با روش های هیدرولوژیکی یکی از اهداف ماست.
آب های زیر سطحی - مبانی و مفاهیم و پروژه های تخصصی
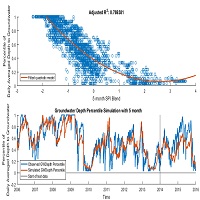
آب های زیر سطحی،اهمیت بسیار زیادی در ارتباط یابی بین منابع آب و گیاهان دارند. خشسالی ها و ترسالی ها در این مفهوم خود را بیشتر برای انسان نشان می دهند. در عین حال مهم است که بدانیم اندرکنش آب های زیرزمینی و آب های سطحی بر اساس وضعیت لایه ای که آب های زیرسطحی در آن واقع شده است روی می دهد. شناخت درست آب های سطحی با روش های هیدرولوژیکی یکی از اهداف ماست.
برنامه نویسی منعطف به زبان پایتون
عنوان مهندسی برازنده فردی است که با معادلات یک علم آشنایی مشخصی داشته باشد. آشنایی با معادلات و مفهومات علم هیدرولوژی امکان کار با زبان های اسکریپت منعطفی چون پایتون را فراهم می کند که در نتیجه بسیاری از مسائل و مشکلات تخصصی و استثنا در مهندسی آب، امکان حل دقیق و کامپیوتری را پیدا کنند.
دریافت داده های مکانی پرکاربرد در مهندسی آب
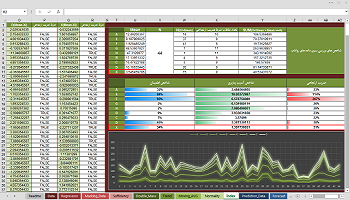
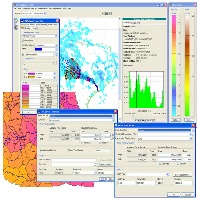
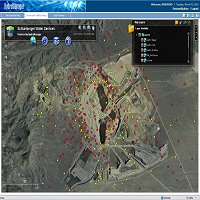
بخش مهمی از خطا در محاسبات مهندسی، منتشر شده از داده های پایه ضعیف است. در این بخش می توانید به مجموعه گسترده ای از داده های مکانی چه در فرمت رستری و چه وکتوری، به منظور استفاده در نرم افزارهای مهندسی دسترسی داشته باشید. به مجموعه به مرور زمان افزوده می شود. همچنین محتوای پیشین در صورت امکان بروزرسانی می شود.
دریافت داده ها و اطلاعات پرکاربرد در مهندسی آب
دامنه وسیع داده ها و اطلاعات محیطی، الزام به دسترسی مطمئن و بروز از این آمار و اطلاعات را نشان می دهد. با توجه به گستردگی منابع دستیابی به داده در سطح اینترنت، ما در اینجا مجموعه بزرگی از داده ها را جمع آوری کرده ایم. شما می تواند به همراه توصیحات به این محتوا دسترسی داشته باشید.