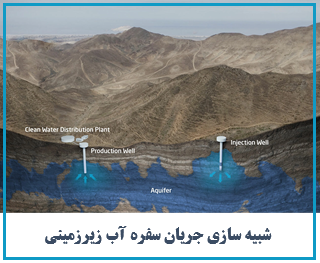
فهرست آموزش - پیش بینی سری زمانی در پایتون

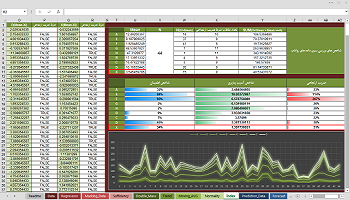
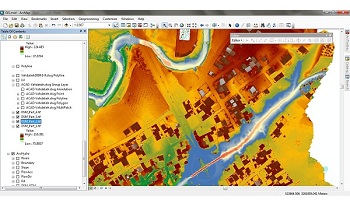
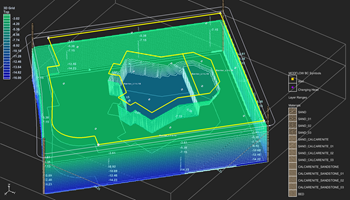
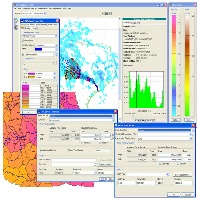
پایتون یک زبان برنامه نویسی ساده و قدرتمند است. از بکارگیری واژه ساده، منظورم این است که آن را بسیار منعطف تر از زبان هایی مانند C می یابید اگر چه کند است. و از واژه قدرتمند، منظورم این است که می توان بسیاری از کدهای موجود را که در C، C++، Fortran و غیره نوشته شده است، به آن چسباند. جامعه کاربر این زبان رو به رشد است که بسیاری از ابزار را به راحتی در دسترس می کند. شاخص پایتون، که یک میزبان بزرگ از کد پایتون است، در حال حاضر دارای بیش از چند ده هزار بسته است، که در مورد محبوبیت آن صحبت می کنند. استفاده از پایتون در جامعه هیدرولوژی نسبت به سایر زمینه ها خیلی سریع نیست، اما امروزه بسیاری از بسته های هیدرولوژیکی جدید در حال توسعه هستند. پایتون دسترسی به ترکیب خوبی از ابزارهای GIS، ریاضیات، و آمار و غیره را فراهم می کند، که باعث می شود یک زبان مفید برای هیدرولوژیست باشد.