



تهیه لایه تنوع پوشش زمین با eo-learn - قسمت 2

پشته ای از تصاویر Sentinel-2 از یک منطقه کوچک در اسلوونی، و به دنبال آن یک پیش بینی پوشش زمین، که از طریق روش های ارائه شده در این پست بدست آمده است. قسمت دوم درباره کاربری اراضی و طبقه بندی پوشش اراضی با eo-Learn در اینجا در دسترس است. این قسمت از امتداد قسمت اول انتخاب می شود، جایی که ما یک رویکرد اساسی در مورد موارد زیر ارائه کردیم:
- تقسیم منطقه مورد علاقه (AOI) به EOPatches
- به دست آوردن داده های تصویر Sentinel-2 و ماسک های ابری
- محاسبه اطلاعات اضافی از جمله شاخص پوشش گیاهی با اختلاف عادی (NDVI)، شاخص آب عادی تفاوت (NDWI)، هنجار اقلیدسی باند های شامل (NORM) و غیره.
- افزودن داده های مرجع شطرنجی از داده های بردار به EOPatches
علاوه بر این، ما به منظور آشنایی بیشتر با داده ها، اکتشاف کردیم که قبل از اینکه در بخش یادگیری ماشین (ML) واقع شوید، بسیار مهم است. وظایف فوق با نمونه ای در قالب نوت بوک Jupyter همراه باشد، که هم اکنون برای پاسخ به مطالب ارائه شده در این بلاگ به روز شده است. ما اکیداً پیشنهاد می کنیم که به اولین پست وبلاگ نگاهی بیندازید و خاطره خود را از آنچه در آنجا ارائه شده است، تازه کنید.
در این بخش، ما بر باقی مانده آماده سازی داده ها، و همچنین آموزش طبقه بندی یادگیری ماشین و ساخت برخی پیش بینی های مربوط به پوشش زمین در اسلوونی برای سال 2017 تمرکز می کنیم.

تهیه داده
بخش یادگیری ماشین واقعی در کل خط پردازش نسبت به کل گردش کار بسیار ناچیز است. بیشتر کارها شامل تمیز کردن داده ها، دستکاری داده ها و تغییر شکل داده ها به منظور دستیابی به استفاده یکپارچه با یک طبقه بندی یادگیری ماشین است. قسمت تهیه داده ها در مراحل شرح داده شده در زیر انجام می شود.
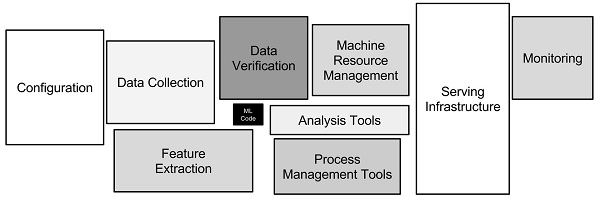
نمودار یک خط یادگیری ماشین، نشان می دهد که کد ML در واقع بخشی نسبتاً کمی از خط ML را نشان می دهد.
فیلتر صحنه ابری
ابرها اشیاء هستند که عموماً در مقیاس های بزرگتر از میانگین EOPatch ما (1000 در 1000 پیکسل با وضوح 10 متر) رخ می دهند. این بدان معناست که یک منطقه به طور تصادفی مشاهده شده می تواند کاملاً توسط ابرها در تاریخ های مشخص پوشانده شود. چنین قاب هایی حاوی هیچ اطلاعات ارزشمندی نیستند و فقط منابع مصرف می کنند، بنابراین با محاسبه نسبت پیکسل های معتبر و تعیین آستانه آنها را از این موارد دور می کنیم. پیکسل های معتبر همه پیکسل هایی هستند که به عنوان ابر طبقه بندی نمی شوند و در داخل ماهواره قرار دارند (آنچه ماهواره می بیند). توجه داشته باشید که ما از متا داده های پوششی ابر صحنه های ماهواره ای استفاده نمی کنیم، زیرا اینها در سطح رستری محاسبه می شوند (اندازه موزاییک 10980 در 10980 پیکسل، که در حدود 110 کیلومتر مربع است) و بنابراین بیشتر برای AOI خاص بی ربط هستند. برای تشخیص ابر، از الگوریتم s2cloudless برای گرفتن پیکسل های ابری واقعی استفاده می کنیم.
در نوت بوک مثال ما، آستانه 0.8 تنظیم شده است، بنابراین فقط فریم های زمانی با نسبت پوشش معتبر بزرگتر از 80٪ انتخاب می شوند. ممکن است این به نظر می رسد آستانه بسیار بالایی باشد، اما از آنجا که پوشش ابر در منطقه مورد علاقه ما چندان مشکل ساز نیست، ما می توانیم از عهده این کار برآییم. با این حال، این مرحله برای همه مکان ها به خوبی تعمیم نمی یابد، زیرا برخی از آنها می توانند برای قسمتهای بیشتر سال ابری باشند.

میانیابی پیکسل ها
با توجه به تاریخ های دستیابی غیر ثابت ماهواره ها و شرایط نامنظم آب و هوا، داده های گمشده در زمینه EO بسیار متداول است. یکی از راه های حل این مشکل استفاده از ماسک پیکسل های معتبر (تعریف شده در مرحله قبل) و درون یابی مقادیر به منظور "پر کردن شکاف ها" است. پس از فرآیند درون یابی، مقادیر پیکسل در تاریخ های یکنواخت یا غیر یکنواخت را می توان مورد ارزیابی قرار داد تا تاریخ ها را بین تمام EOPatches متحد سازد. در این مثال، روش درون یابی خطی را اعمال می کنیم، اما روش های دیگر نیز کاربردی هستند و قبلاً در آموزش EO نیز اجرا شده اند.

نمایش تصویری از یک پشته زمانی از تصاویر Sentinel-2 در یک منطقه به طور تصادفی انتخاب شده است. پیکسل های شفاف در سمت چپ حاکی از عدم وجود داده به دلیل پوشش ابر است. پشته در سمت راست، مقادیر پیکسل را بعد از درون یابی موقتی نشان می دهد، و ماسک های ابری را در نظر می گیرد.
اطلاعات موقتی در طبقه بندی پوشش اراضی و حتی بیشتر در طبقه بندی نوع محصول بسیار مهم است. این در شرایطی است که اطلاعات زیادی در مورد پوشش اراضی در تکامل موقتی زمین تعبیه شده است. به عنوان مثال، با نگاهی به مقادیر درون یابی NDVI، می توانید در تصویر زیر مشاهده کنید که مقادیر مربوط به جنگل و نوع سطح زیر کشت در اوایل بهار / تابستان و افت در پاییز / زمستان، در حالی که برای سطح آب و سطح مصنوعی این مقادیر را تایپ می کنید. بیشتر در طول سال بدون تغییر باقی می مانند. نوع سطح مصنوعی مقادیر کمی بزرگتر NDVI دارد و تا حدودی از تکامل موقتی اراضی گیاهی تقلید می کند به دلیل اینکه مناطق شهری اغلب از درختان و پارک های کوچک تشکیل شده اند. علاوه بر این، با توجه به وضوح کارآمد مقادیر پیکسل می تواند از پاسخ های طیفی ترکیبی از چندین نوع پوشش مختلف زمین تشکیل شده باشد.
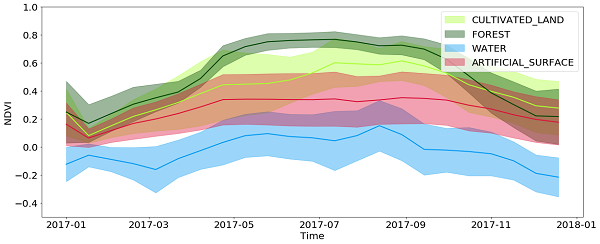
تکامل موقتی مقادیر NDVI برای پیکسل های نوع پوشش اراضی منتخب در طول سال.
برنامه بافر منفی
در حالی که وضوح 10 متر ماهواره های Sentinel-2 به اندازه کافی برای طیف گسترده ای از برنامه ها مناسب است، اما تأثیر اشیاء کوچکتر از آن قابل توجه است. چنین نمونه هایی مرزهایی بین انواع مختلف پوشش زمین است، جایی که مقادیر پیکسل ها حاوی امضاهایی از هر دو نوع همسایه هستند اما فقط در یکی از دو کلاس در نقشه مرجع قرار دارند. این امر باعث ایجاد نویز در هنگام آموزش طبقه بندی می شود و در مرحله پیش بینی، دقت طبقه بندیگر پایین می آید. علاوه بر این، شبکه های جاده ای یا اشیاء دیگر با عرض 1 پیکسل، که در نقشه مرجع تعریف شده اند، از داده های تصویر به راحتی قابل تشخیص نیستند. ما یک بافر منفی از اندازه 1 پیکسل را بر روی نقشه مرجع اعمال می کنیم، و تقریباً اکثر موارد را از بین می بریم. نقشه مرجع مورد استفاده در اینجا همان نقشه ای است که در پست قبل معرفی شده است. بخشی از آن را می توانید در تصویر زیر برای این پرونده قبل یا بعد از استفاده از بافر منفی مشاهده کنید.
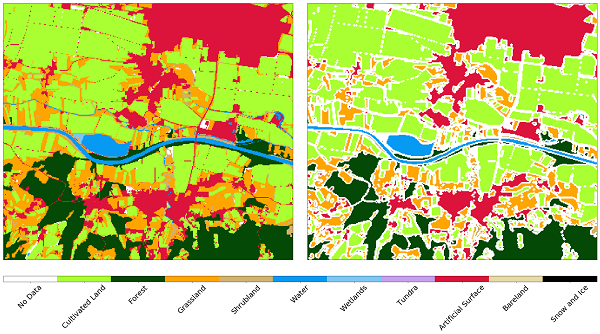
نقشه مرجع برای بخش کوچکی از AOI قبل (چپ) و بعد از (راست) استفاده از بافر منفی روی نقشه.
انتخاب زیر مجموعه تصادفی
همانطور که در پست قبلی ذکر شد، منطقه مورد علاقه (AOI) به حدود 300 EOPatches تقسیم می شود، جایی که هر پچ از حدود 1 میلیون پیکسل تشکیل شده است. این تعداد پیکسل بسیار زیاد است، که همه آنها را به خود اختصاص می دهد، بنابراین ما به طور یکنواخت در حدود 40000 پیکسل در هر EOPatch نمونه می گیریم تا یک مجموعه داده از حدود 12 میلیون مدخل بدست آوریم. از آنجا که پیکسل ها به طور یکنواخت نمونه برداری شده اند، بسیاری از آنها حاوی برچسب "بدون داده" هستند، که اطلاعات مربوط به حقیقت زمین در دسترس نیست. چنین ورودی هایی فاقد فایده ای هستند و به منظور عدم سردرگمی طبقه بندی و آموزش آن برای پیش بینی برچسب "بدون داده" از مجموعه آموزش حذف می شوند. ما این کار را برای مجموعه اعتبار سنجی نیز تکرار می کنیم زیرا چنین نوشته هایی به طور غیر منطقی دقت و سایر نمرات مشابه طبقه بندیگر را در مرحله اعتبار سنجی پایین می آورند.

تقسیم و تغییر شکل داده ها
تقسیم قطار / آزمون را در سطح EOPatch در حدود 80/20 درصد قرار می دهیم، به این معنی که پیکسل های EOPatches مورد استفاده برای آموزش برای آزمایش استفاده نشده اند و بالعکس. پیکسل های آموزش EOPatches به مجموعه آموزش و اعتبار سنجی متقابل به همان شیوه تقسیم می شوند. پس از تقسیم، یک شیء numpy.ndarray از شکل (p ، t ، w ، h ، d) داریم که در آن p تعداد EOPatches در زیر مجموعه است، t تعداد فریمهای بازسازی شده مجدد برای هر EOPatch است، و w ، h و d به ترتیب عرض، ارتفاع و عمق EOPatches هستند. پس از انتخاب زیر مجموعه، عرض w به تعداد پیکسل های انتخاب شده مطابقت دارد (به عنوان مثال 40000 به بالا)، در حالی که بعد ارتفاع h برابر است با 1. تفاوت در شکل آرایه هیچ چیزی را تغییر نمی دهد، فقط پیکسل ها را دوباره مرتب می کند. استفاده از آنها ساده تر است. باند ها و ویژگی های باند مانند d در همه فریم های زمان t، ورودی های طبقه بندی شده مورد استفاده برای آموزش را نشان می دهند، جایی که تعداد ورودی های ورودی * در آنها وجود دارد. برای تبدیل داده ها به شکلی که توسط طبقه بندی پذیرفته شده است، باید آنرا از آرایه 5D به یک آرایه 2D از فرم (p * w * h ، d * t) تغییر شکل دهیم که می توان با موارد زیر انجام داد.
| import numpy as np p, t, w, h, d = features_array.shape | |
| # move t axis from position 1 to position 3 | |
| features_array = np.moveaxis(features_array, 1, 3) | |
| # reshape array | |
| features_array = features_array.reshape(p*w*h, t*d) |
چنین روشی سپس اجازه می دهد تا داده های جدید با همان شکل پیش بینی شود، و سپس آن را به تکه های شکل اصلی تبدیل کنید، که می تواند مجدداً با تکنیک های ترسیم استاندارد تجسم یابد.
ساخت مدل یادگیری ماشین
انتخاب بهینه یک طبقه بندیگر به شدت بستگی به کاربرد دارد و حتی در این صورت تعدادی پارامتر از مدل نیز وجود دارند که باید برای یک برنامه خاص تنظیم شوند. برای بهینه سازی این گزینه ها، باید در اصل چندین آزمایش انجام داده و نتایج را با یکدیگر مقایسه کرد.
در رویکرد ما به طبقه بندی، از بسته LightGBM استفاده می کنیم، زیرا چارچوبی تقویت کننده شیب بصری، سریع، توزیع شده و عملکرد بالا را بر اساس الگوریتم های درخت تصمیم ارائه می دهد. برای تنظیم پارامترهای طبقه بندیگر، رویکردهای مختلفی مانند جستجوی شبکه یا جستجوی تصادفی را می توان در مجموعه داده آزمون پیگیری و ارزیابی کرد. برای اهداف این مثال، ما این مراحل را رد می کنیم و از پارامترهای پیش فرض استفاده می کنیم.
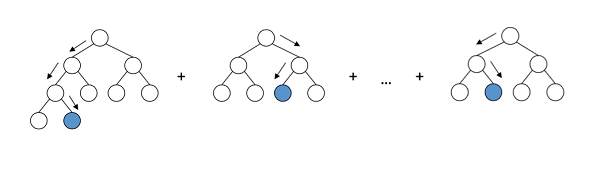
شماتیک درختان تصمیم گیری در چارچوب LightGBM.
اجرای مدل بسیار ساده است و از آنجا که داده ها از قبل در قالب آرایه مناسب 2D شکل گرفته اند، ما فقط آن را به مدل عرضه می کنیم و منتظر می مانیم. تبریک می گویم! اکنون می توانید به همه بگویید که شما در حال انجام مدل یادگیری ماشین هستید.
اعتبارسنجی مدل
آموزش مدل های یادگیری ماشین آسان است. بخش سخت این است که آنها را به خوبی آموزش دهید. برای انجام این کار، به یک الگوریتم مناسب، یک مرجع مطمئن نیاز داریم نقشه erence، و منابع کافی CPU / حافظه. حتی در این صورت ممکن است نتایج مورد نظر شما نباشد، بنابراین اعتبار سنجنده طبقه بندی با محاسبه ماتریس های سردرگمی و سایر معیارهای اعتبار سنجی، اگر بخواهید اعتبار خود را به کار خود اضافه کنید، بسیار مهم است.
ماتریس سردرگمی
ماتریس های سردرگمی اولین چیزی است که به منظور ارزیابی عملکرد مدل می توان به آن نگاه کرد. آنها تعدادی از برچسب های درست و نادرست پیش بینی شده برای هر برچسب را از نقشه مرجع یا برعکس نشان می دهند. معمولاً یک ماتریس سردرگمی عادی نشان داده می شود، که در آن تمام مقادیر موجود در ردیف ها بر جمع آنها تقسیم می شود. این نشان خواهد داد که اگر طبقه بندیگر نسبت به طبقه بندی نادرست انواع خاصی از پوشش اراضی سوگیری داشته باشد.
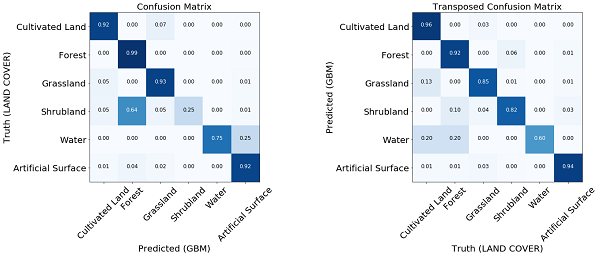
دو جنبه مشاهده ماتریس سردرگمی عادی یک مدل آموزش دیده.
برای اکثر کلاس ها، به نظر می رسد که این مدل عملکرد خوبی دارد. به دلیل مجموعه آموزش نامتعادل، برای برخی از کلاس ها مشکلاتی رخ می دهد. ما می بینیم که موارد مشکل ساز، به عنوان مثال، بوته و آب است که در آن پیکسل های واقعی متعلق به این کلاس ها مانند سایر کلاس ها قابل شناسایی هستند. از طرف دیگر، آنچه که به عنوان بوته یا آب پیش بینی شده است، با نقشه مرجع مطابقت دارد. در تصویر زیر مشاهده می کنیم که مشکلات به طور کلی برای کلاس های زیر نماینده اتفاق می افتد، بنابراین باید در نظر داشته باشید که این گفته ها فقط سطحی هستند، زیرا نمونه آموزش در این مثال نسبتاً اندک است و فقط به عنوان اثبات اصل عمل می کند.
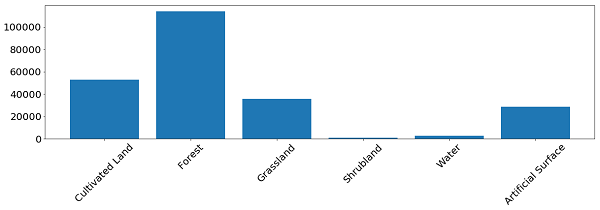
فرکانس پیکسل برای هر کلاس در مجموعه داده های آموزش. به طور کلی، توزیع یکنواخت نیست.
ویژگی گیرنده گیرنده - منحنی ROC
طبقه بندیگرها برچسب ها را با اطمینان خاصی پیش بینی می کنند، اما آستانه پیش بینی یک برچسب خاص قابل دستکاری است. منحنی ROC توانایی تشخیص طبقه بندی کننده را نشان می دهد زیرا آستانه تبعیض آن متنوع است. معمولاً برای سیستم دودویی نشان داده می شود، اما می تواند در طبقه بندی های چند کلاسی نیز مورد استفاده قرار گیرد، جایی که ویژگی های "یک در مقابل رست" را برای هر کلاس ارائه شده محاسبه می کنیم. محور x میزان مثبت کاذب را نشان می دهد (ما می خواهیم کوچک باشد) و محور y میزان مثبت واقعی (ما می خواهیم بزرگ باشد) را در آستانه های مختلف نشان می دهد. عملکرد طبقه بندی خوب با یک منحنی مشخص می شود، که دارای یک مقدار انتگرال بزرگ است، همچنین به عنوان منطقه زیر منحنی (AUC) شناخته می شود. نتیجه گیری مشابه در مورد کلاس های کم نماینده بر اساس طرح زیر می تواند برای بوته ها انجام شود، در حالی که منحنی ROC برای آب بسیار بهتر به نظر می رسد، زیرا آب بسیار راحت تر قابل تشخیص است، حتی اگر کم نما باشد.
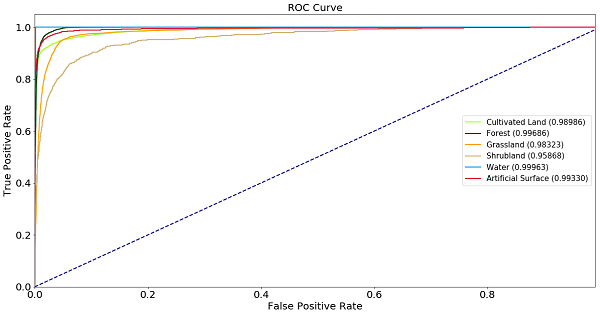
منحنی های ROC طبقه بندی شده، که برای هر کلاس در مجموعه داده به عنوان "یک در مقابل رست" نمایش داده می شود. تعداد براکت ها مقادیر زیر منحنی ناحیه زیر (AUC) هستند.
اهمیت ویژگی
با نگاه به اهمیت ویژگی، می توان بینش عمیق تری از عملکردهای پیچیده طبقه بندی بدست آورد، که به ما می گوید کدام ویژگی ها بیشترین اثر را در نتایج نهایی داشته است. برخی از الگوریتم های یادگیری ماشین، مانند نمونه ای که در این مثال از آنها استفاده می کنیم، این مقادیر را به عنوان یک خروجی باز می گردانند، در حالی که برای دیگر موارد، این مقادیر باید جداگانه محاسبه شوند. طرح زیر اهمیت هر ویژگی در هر تاریخ خاص را نشان می دهد.
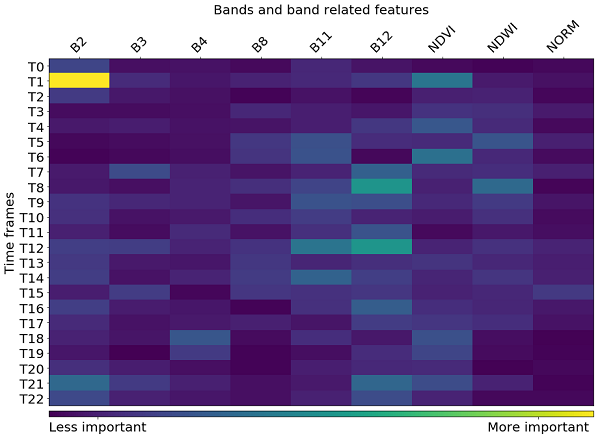
نقشه اهمیت ویژگی برای ویژگی های مورد استفاده در این طبقه بندی.
در حالی که سایر ویژگی ها (به عنوان مثال NDVI) در بهار به طور کلی اهمیت بیشتری دارند، می بینیم که تاریخ خاصی وجود دارد که یکی از باند ها (B2 - آبی) مهمترین ویژگی باشد. با نگاهی دقیقتر، معلوم می شود که منطقه در آن زمان با برف پوشیده شده بود. به نظر می رسد پوشش برفی از اطلاعاتی در مورد بافت زیرین پرده برمی دارد، که به طبقه بندی کننده کمک می کند تا نوع صحیح پوشش سطح زمین را تعیین کند. با این حال، باید در نظر داشته باشید که این واقعیت مختص AOI است که شما مشاهده می کنید و به طور کلی نمی توان به آنها اعتماد کرد.

بخشی از این AOI متشکل از 3/3 EOPatches پوشیده از برف است.
نتایج پیش بینی
با اعتبار سنجی انجام شده، اکنون نقاط قوت و ضعف مدل پیش بینی خود را می فهمیم. اگر از وضعیت راضی نباشیم، می توان جریان کار را تغییر داد و دوباره امتحان کرد. پس از بهینه سازی مدل، یک EOTask ساده را تعریف می کنیم که EOPatch و مدل طبقه بندیگر را می پذیرد، پیش بینی را انجام می دهد و آن را بر روی پچ اعمال می کند.
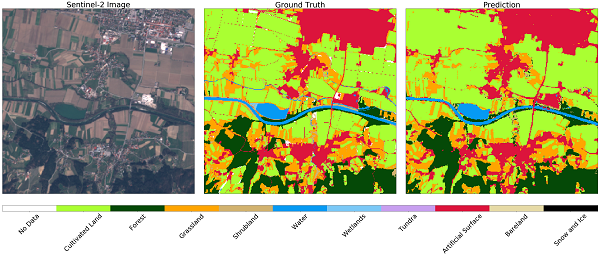
تصویر Sentinel-2 (سمت چپ)، حقیقت زمین (مرکز) و پیش بینی (سمت راست) برای EOPatch تصادفی در AOI انتخاب شده. برخی اختلافات قابل مشاهده است که بیشتر به دلیل استفاده از بافر منفی در نقشه مرجع است، در غیر این صورت توافق برای این مورد استفاده رضایت بخش است.
از این به بعد مسیر مشخص است. روش را برای همه EOPatches تکرار کنید. شما حتی می توانید پیش بینی ها را به عنوان تصاویر GeoTIFF صادر کرده و آنها را با gdal_merge.py ادغام کنید.
ما GeoTIFF ادغام شده را نیز در پورتال CloudGIS Geopedia بارگذاری کردیم، بنابراین می توانید نتایج را با جزئیات بیشتر در آنجا مشاهده کنید.
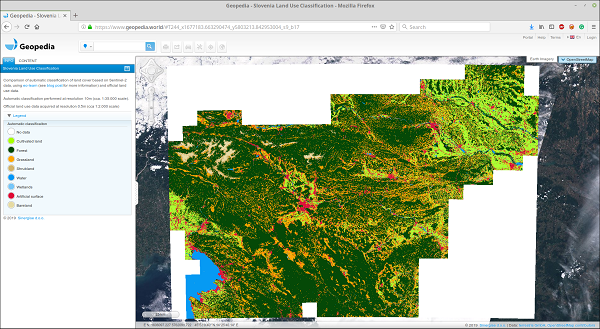
تصویر پیش بینی پوشش زمین برای اسلوونی 2017 با استفاده از رویکرد نشان داده شده در این پست، برای مرور دقیق در پرتال CloudGIS Geopedia در دسترس است.
همچنین می توانید داده های رسمی کاربری اراضی را با داده های پوشش طبقه بندی شده به صورت خودکار طبقه بندی کنید. توجه داشته باشید که تفاوت کاربری و پوشش اراضی، که یک چالش مشترک در فرآیندهای ML است - نقشه نویسی همیشه از کلاسهایی که در ثبت های رسمی استفاده می شود تا کلاس هایی که در طبیعت مشاهده می شوند، آسان نیست. برای نشان دادن این چالش، دو فرودگاه در اسلوونی را نشان می دهیم. اولین مورد در لویک، در نزدیکی شهر سلژ است. این فرودگاه ورزشی کوچک است، بیشتر برای هواپیماهای خصوصی استفاده می شود و از چمن پوشیده شده است. داده های رسمی کاربری زمین نوار فرود پوشیده از چمن را به عنوان سطح مصنوعی نشان می دهد، در حالی که طبقه بندی کننده قادر است به طور صحیح پوشش زمین را به عنوان مرتع پیش بینی کند، همانطور که در زیر آمده است.
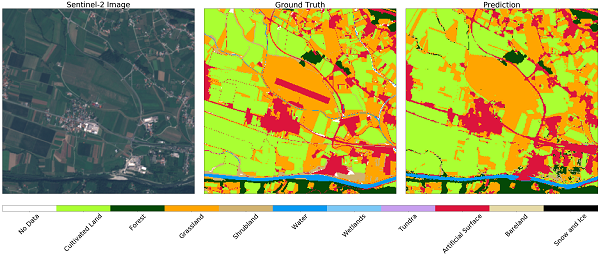
تصویر Sentinel-2 (سمت چپ)، حقیقت زمین (مرکز) و پیش بینی (سمت راست) برای منطقه اطراف فرودگاه کوچک ورزشی Levec، در نزدیکی Celje، اسلوونی. طبقه بندی کننده صحیح نوار فرود را به عنوان مرتع می شناسد که در داده های رسمی کاربرد اراضی به عنوان سطح مصنوعی مشخص شده است.
از طرف دیگر، با نگاهی به فرودگاه لیوبلیانا Jože Pučnik، بزرگترین فرودگاه اسلوونی، مناطقی که به عنوان سطح مصنوعی در داده های رسمی استفاده از اراضی مشخص شده اند، مناطق باند فرودگاه و شبکه های جاده ای هستند. در این حالت، طبقه بندیگر قادر به شناسایی مناطق ساخته شده است، در حالی که هنوز هم به درستی می توان مرتع و زمین های زراعی را در مکان های اطراف شناسایی کرد.
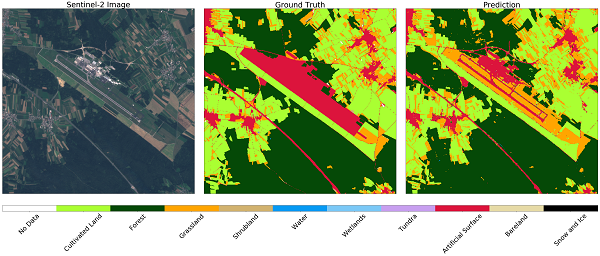
تصویر Sentinel-2 (سمت چپ)، حقیقت زمین (مرکز) و پیش بینی (سمت راست) برای منطقه اطراف فرودگاه لیوبلیانا Jože Pučnik، بزرگترین فرودگاه اسلوونی است. طبقه بندی کننده باند و شبکه راه را تشخیص می دهد، در حالی که هنوز هم به طور صحیح مرتع و زمین های زراعی را در منطقه اطراف خود شناسایی می کند.
حالا شما می دانید چگونه می توانید یک پیش بینی قابل اعتماد را در مقیاس کشور تهیه کنید! حتماً آن را در CV خود قرار دهید. اگر می خواهید به پیشرفت ابزارهای EO عالی بپردازید، فراموش نکنید که آن را برای ما ارسال کنید.
ما همچنین قصد داریم قسمت 3، آخرین قسمت از این سری را منتشر کنیم، که در آن نحوه آزمایش جریان کار ML را نشان خواهیم داد و برای بهبود نتایج تلاش خواهیم کرد! علاوه بر این، ما به صورت آشکار همه EOPatches برای اسلوونی 2017 را به اشتراک خواهیم گذاشت - درست است، شما به درستی شنیده اید، تمام مجموعه داده ها، حاوی داده های Sentinel-2 L1C، ماسک های ابر s2cloud، داده های مرجع و غیره، بنابراین همه می توانند آن را امتحان کنند!

مدیر سایت: بهزاد سرهادی کارشناس ارشد مهندسی آب
شناسه تلگرام مدیر سایت: SubBasin@
نشانی ایمیل: behzadsarhadi@gmail.com
(سوالات تخصصی را در گروه تلگرام ارسال کنید)
_______________________________________________________
پروژه تخصصی در لینکدین



 در منابع آب
در منابع آب


























نظرات (۰)