



ماشین بردار پشتیبانی و پیش بینی سری زمانی داده های آب
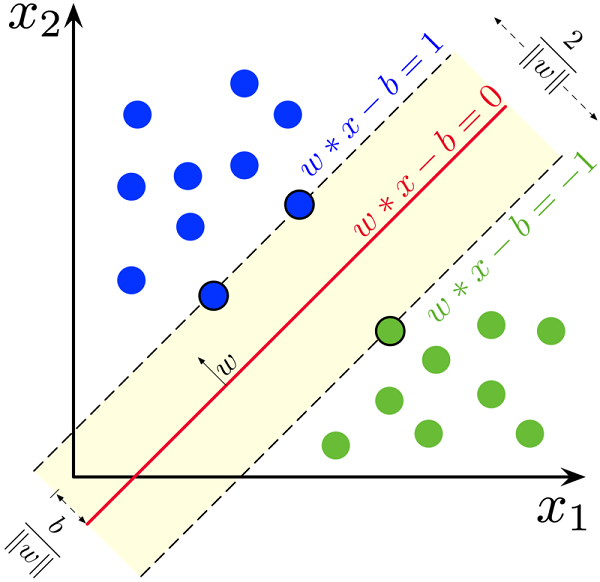
ماشین بردار پشتیبانی (Support vector machines - SVMs) یکی از روشهای یادگیری با نظارت است که از آن برای طبقهبندی و رگرسیون استفاده میکنند. این روش از جملهٔ روشهای نسبتاً جدیدی است که در سالهای اخیر کارایی خوبی نسبت به روشهای قدیمیتر برای طبقهبندی نشان دادهاست. مبنای کاری دستهبندی کنندهٔ SVM دستهبندی خطی دادهها است و در تقسیم خطی دادهها سعی میکنیم خطی را انتخاب کنیم که حاشیه اطمینان بیشتری داشته باشد. حل معادله پیدا کردن خط بهینه برای دادهها به وسیله روشهای QP که روشهای شناخته شدهای در حل مسائل محدودیتدار هستند صورت میگیرد. قبل از تقسیمِ خطی برای اینکه ماشین بتواند دادههای با پیچیدگی بالا را دستهبندی کند دادهها را به وسیلهٔ تابعِ phi به فضای با ابعاد خیلی بالاتر میبریم. برای اینکه بتوانیم مسئله ابعاد خیلی بالا را با استفاده از این روشها حل کنیم از قضیه دوگانی لاگرانژ برای تبدیلِ مسئلهٔ مینیممسازی مورد نظر به فرم دوگانی آن که در آن به جای تابع پیچیدهٔ phi که ما را به فضایی با ابعاد بالا میبرد، تابعِ سادهتری به نامِ تابع هسته که ضرب برداری تابع phi است ظاهر میشود استفاده میکنیم. از توابع هسته مختلفی از جمله هستههای نمایی، چندجملهای و سیگموید میتوان استفاده نمود.
ماشین های بردار پشتیبانی (SVM) مجموعه ای از روش های یادگیری نظارت شده است که برای طبقه بندی، رگرسیون و تشخیص داده های پرت استفاده می شود.
مزایای ماشین های بردار پشتیبانی عبارتند از:
- در فضاهای با ابعاد بالا موثر است.
- هنوز هم در مواردی که تعداد ابعاد از تعداد نمونه بیشتر باشد، موثر است.
- در عملکرد تصمیم گیری از زیر مجموعه ای از نکات آموزشی استفاده می کند (بردارهای پشتیبانی نامیده می شوند)، بنابراین حافظه نیز کارآمد است.
- همه کاره: توابع مختلف هسته را می توان برای عملکرد تصمیم گیری کرد. هسته های متداول ارائه شده است، اما امکان تعیین هسته های سفارشی نیز وجود دارد.
از معایب ماشین های بردار پشتیبانی می توان به موارد زیر اشاره کرد:
اگر تعداد ویژگی ها بسیار بیشتر از تعداد نمونه ها است، از انتخاب بیش از حد در توابع هسته جلوگیری کنید و اصطلاح تنظیم آن بسیار مهم است.
SVM ها تخمین احتمالات را مستقیماً ارائه نمی دهند، اینها با استفاده از اعتبار سنجی متقابل پنج برابر گران محاسبه می شوند (به نمرات و احتمالات در زیر مراجعه کنید).
ماشین های بردار پشتیبانی در scikit-learn از بردارهای نمونه متراکم (numpy.ndarray و قابل تبدیل به آن توسط numpy.asarray) و تجزیه (هر scipy.sparse) پشتیبانی می کنند. با این حال، برای استفاده از SVM برای پیش بینی داده های پراکنده، باید بر روی چنین داده هایی تناسب داشته باشد. برای عملکرد مطلوب، از numpy.ndarray (متراکم) یا scipy.sparse.csr_matrix (پراکنده) با دستور C با dtype = float64 استفاده می شود.
رگرسیون
روش طبقه بندی بردار پشتیبانی را می توان برای حل مسائل رگرسیون گسترش داد. به این روش Support Vector Regression گفته می شود.
مدل تولید شده توسط طبقه بندی بردار پشتیبانی فقط به زیرمجموعه ای از داده های آموزش بستگی دارد، زیرا تابع هزینه ساخت مدل به نقاط آموزشی فراتر از حاشیه اهمیتی نمی دهد. به طور مشابه، مدل تولید شده توسط Support Vector Regression تنها به زیرمجموعه ای از داده های آموزش بستگی دارد، زیرا تابع هزینه نمونه هایی را که پیش بینی آنها نزدیک به هدف است، نادیده می گیرد.
سه پیاده سازی مختلف از رگرسیون برداری پشتیبانی وجود دارد: SVR ،NuSVR و LinearSVR. LinearSVR پیاده سازی سریع تری نسبت به SVR فراهم می کند اما فقط هسته خطی را در نظر می گیرد، در حالی که NuSVR فرمولی کمی متفاوت از SVR و LinearSVR را پیاده سازی می کند.
همانند کلاسهای طبقه بندی، روش fit به عنوان بردارهای آرگومان X، y در نظر گرفته می شود، فقط در این حالت انتظار می رود y به جای مقادیر صحیح، دارای مقادیر شناور باشد:
>>> from sklearn import svm >>> X = [[0, 0], [2, 2]] >>> y = [0.5, 2.5] >>> regr = svm.SVR() >>> regr.fit(X, y) SVR() >>> regr.predict([[1, 1]]) array([1.5])

مدیر سایت: بهزاد سرهادی کارشناس ارشد مهندسی آب
شناسه تلگرام مدیر سایت: SubBasin@
نشانی ایمیل: behzadsarhadi@gmail.com
(سوالات تخصصی را در گروه تلگرام ارسال کنید)
_______________________________________________________
پروژه تخصصی در لینکدین



 در منابع آب
در منابع آب


























نظرات (۰)